Lately we’ve been fleshing out our testing frameworks for Juju and Juju Charms. There’s lots of great stuff going on here, so we figured it’s time to start posting about it.
First off, the coolest thing we did during last month’s Ubuntu Developer Summit (UDS) was get the go-ahead to spend more time/effort/money scale-testing Juju.
The Plan
- pick a service that scales
- spin up a cluster of units for this service
- try to run it in a way that actively engages all units of the cluster
- repeat:
- instrument
- profile
- optimize
- grow
James, Kapil, Juan, Ben, and Mark sat down over the course of a couple of nights at UDS to take a crack at it. We chose Hadoop. We started with 40 nodes and iterated up 100, 500, 1000 and 2000. Here’re some notes on the process.
Hadoop
Hadoop was a pretty obvious choice here. It’s a great actively-maintained project with a large community of users. It scales in a somewhat known manner, and the hadoop charm makes it super-simple to manage. There are also several known benchmarks that are pretty straightforward to get going, and distribute load throughout the cluster.
There’s an entire science/art to tuning hadoop jobs to run optimally given the characteristics of a particular cluster. Our sole goal in tuning hadoop benchmarks was to engage the entire cluster and profile juju during various activities throughout an actual run. For our purposes, we’re in no hurry… a slower/longer run gives us a good profiling picture for managing the nodes themselves under load (with a sufficient mix of i/o -vs- cpu load).
EC2
Surprisingly enough, we don’t really have that many servers just lying around… so EC2 to the rescue.
Disclaimer… we’re testing our infrastructure tools here, not benchmarking hadoop in EC2. Some folks advocate running hadoop in a cloudy virtualized environment… while some folks are die-hard server huggers. That’s actually a really interesting discussion. It comes down to the actual jobs/problems you’re trying to solve and how those jobs fit in your data pipeline. Please note that we’re not trying to solve that problem here or even provide realistic benchmarking data to contribute to the discussion… we’re simply testing how our infrastructure tools perform at scale.
If you do run hadoop in EC2, Amazon’s Elastic Map Reduce service is likely to perform better at scale in EC2 than just running hadoop itself on general purpose instances. Amazon can do all sorts of stuff internally to show hadoop lots of love. We chose not to use EMR because we’re interested in testing how juju performs with generic Ubuntu Server images, not EMR… at least for now.
Note that stock EC2 accounts limit you to something like 20 instances. To grow beyond that, you have to ask AWS to bump up your limits.
Juju
We started scale testing from a fresh branch of juju trunk… what gets deployed to the PPA nightly… this freed us up to experiment with live changes to add instrumentation, profiling information, and randomly mess with code as necessary. This also locks in the branch of juju that the scale testing environment uses.
As usual, juju will keep track of the state of our infrastructure going forward and we can make changes as necessary via juju commands. To bootstrap and spin up the initial environment we’ll just use shell scripts wrapping juju commands.
Spinning up a cluster
These scripts are really just hadoop versions of some standard juju demo scripts such as those used for a simple rails stack or a more realistic HA wiki stack.
The hadoop scripts for EC2 will get a little more complex as we grow simply because we don’t want AWS to think we’re a DoS attack… we’ll pace ourselves during spinup.
From the hadoop charm’s readme, the basic steps to spinning up a simple combined hdfs and mapreduce cluster are:
juju bootstrap
juju deploy hadoop hadoop-master
juju deploy -n3 hadoop hadoop-slavecluster
juju add-relation hadoop-master:namenode hadoop-slavecluster:datanode
juju add-relation hadoop-master:jobtracker hadoop-slavecluster:tasktracker
which we expand on a bit to start with a base startup script that looks like:
#!/bin/bash
juju_root="/home/ubuntu/scale"
juju_env=${1:-"-escale"}
###
echo "deploying stack"
juju bootstrap $juju_env
deploy_cluster() {
local cluster_name=$1
juju deploy $juju_env --repository "$juju_root/charms" --constraints="instance-type=m1.large" --config "$juju_root/etc/hadoop-master.yaml" local:hadoop ${cluster_name}-master
juju deploy $juju_env --repository "$juju_root/charms" --constraints="instance-type=m1.medium" --config "$juju_root/etc/hadoop-slave.yaml" -n 37 local:hadoop ${cluster_name}-slave
juju add-relation $juju_env ${cluster_name}-master:namenode ${cluster_name}-slave:datanode
juju add-relation $juju_env ${cluster_name}-master:jobtracker ${cluster_name}-slave:tasktracker
juju expose $juju_env ${cluster_name}-master
}
deploy_cluster hadoop
echo "done"
and then manually adjust this for cluster size.
Configuring Hadoop
Note that we’re specifying constraints to tell juju to use different sized ec2 instances for different juju services. We’d like an m1.large for the hadoop master
juju deploy ... --constraints "instance-type=m1.large" ... hadoop-master
and m1.mediums for the slaves
juju deploy ... --constraints "instance-type=m1.medium" ... hadoop-slave
Note that we’ll also pass config files to specify different heap sizes for the different memory footprints
juju deploy ... --config "hadoop-master.yaml" ... hadoop-master
where hadoop-master.yaml looks like
# m1.large
hadoop-master:
heap: 2048
dfs.block.size: 134217728
dfs.namenode.handler.count: 20
mapred.reduce.parallel.copies: 50
mapred.child.java.opts: -Xmx512m
mapred.job.tracker.handler.count: 60
# fs.inmemory.size.mb: 200
io.sort.factor: 100
io.sort.mb: 200
io.file.buffer.size: 131072
tasktracker.http.threads: 50
hadoop.dir.base: /mnt/hadoop
and
juju deploy ... --config "hadoop-slave.yaml" ... hadoop-slave
where hadoop-slave.yaml looks like
# m1.medium
hadoop-slave:
heap: 1024
dfs.block.size: 134217728
dfs.namenode.handler.count: 20
mapred.reduce.parallel.copies: 50
mapred.child.java.opts: -Xmx512m
mapred.job.tracker.handler.count: 60
# fs.inmemory.size.mb: 200
io.sort.factor: 100
io.sort.mb: 200
io.file.buffer.size: 131072
tasktracker.http.threads: 50
hadoop.dir.base: /mnt/hadoop
Note also that we also have our juju environment configured to use
instance-store images… juju defaults to ebs-rooted images, but that’s
not a great idea with hdfs. You specify this by adding a default-image-id
into your ~/.juju/environments.yaml file.
This gave each of our instances an extra ~400G local drive
on /mnt… hence the hadoop.dir.base of /mnt/hadoop
in the config above.
40 nodes and 100 nodes
Both the 40-node and 100-node runs went as smooth as silk. The only thing to note was that it took a while to get AWS to increase our account limits to allow for 100+ nodes.
500 nodes
Once we had permission from Amazon to spin up 500 nodes on our account, we initially just naively spun up 500 instances… and quickly got throttled.
No particular surprise, we’re not specifying multiplicity in the ec2 api, nor are we using an auto scaling group… we must look like a DoS attack.
The order was eventually fulfilled, and juju waited around for it. Everything ran as expected, it just took about an hour and 15 minutes to spin up the stack. This gave us a nice little cluster with HDFS storage of almost 200TB

The hadoop terasort job was run from the following script
#!/bin/bash
SIZE=10000000000
NUM_MAPS=1500
NUM_REDUCES=1500
IN_DIR=in_dir
OUT_DIR=out_dir
hadoop jar /usr/lib/hadoop/hadoop-examples*.jar teragen -Dmapred.map.tasks=${NUM_MAPS} ${SIZE} ${IN_DIR}
sleep 10
hadoop jar /usr/lib/hadoop/hadoop-examples*.jar terasort -Dmapred.reduce.tasks=${NUM_REDUCES} ${IN_DIR} ${OUT_DIR}
which, with a replfactor of 3, engaged the entire cluster just fine, and ran terasort with no problems
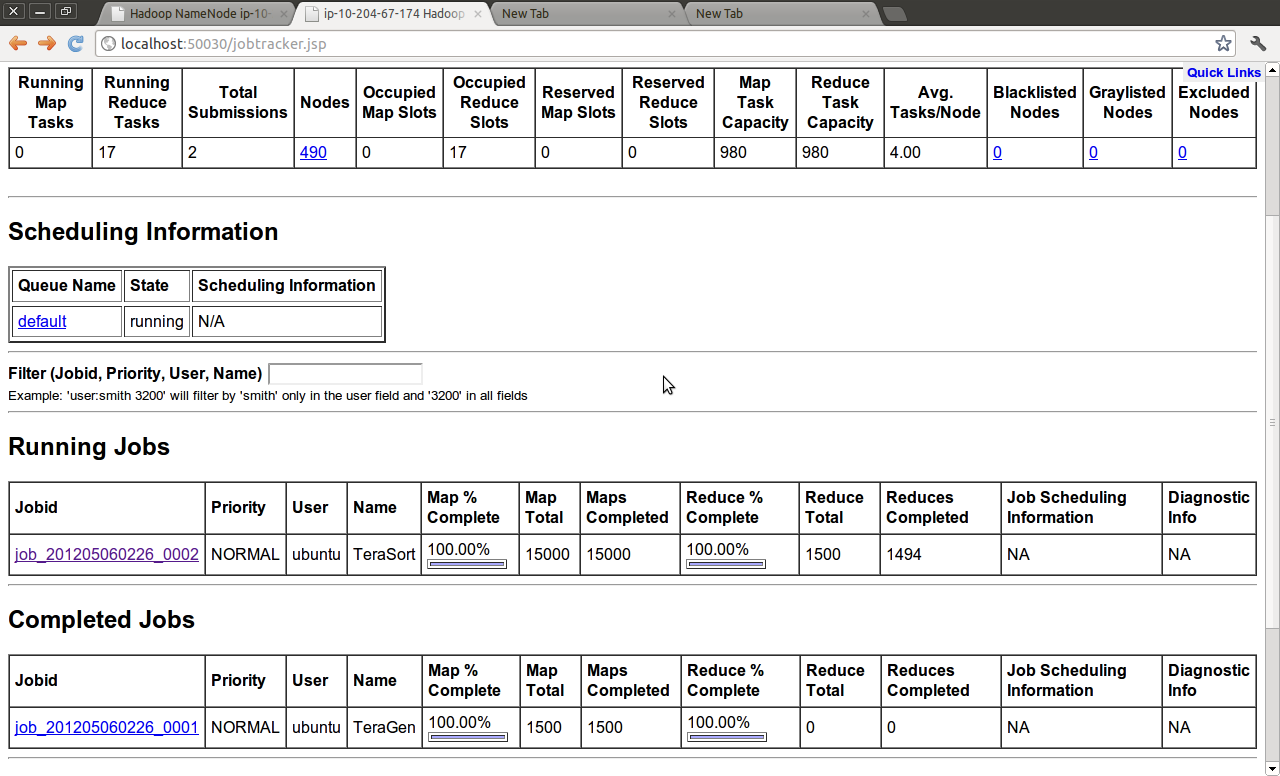
Juju itself seemed to work great in this run, but this brought up a couple of basic optimizations against the EC2 api:
- pass the '-n' options directly to the provisioning agent... don't expand `juju deploy -n <num_units>` and `juju add-unit -n <num_units>` in the client
- pass these along all the way to the ec2 api... don't expand these into multiple api calls
We’ll add those to the list of things to do.
1000 nodes
Onward, upward!
To get around the api throttling, we start up batches of 99 slaves at a time with a 2-minute wait between each batch
#!/bin/bash
juju_env=${1:-"-escale"}
juju_root="/home/ubuntu/scale"
juju_repo="$juju_root/charms"
############################################
timestamp() {
date +"%G-%m-%d-%H%M%S"
}
add_more_units() {
local num_units=$1
local service_name=$2
echo "sleeping"
sleep 120
echo "adding another $num_units units at $(timestamp)"
juju add-unit $juju_env -n $num_units $service_name
}
deploy_slaves() {
local cluster_name=$1
local slave_config="$juju_root/etc/hadoop-slave.yaml"
local slave_size="instance-type=m1.medium"
local slaves_at_a_time=99
#local num_slave_batches=10
juju deploy $juju_env --repository $juju_repo --constraints $slave_size --config $slave_config -n $slaves_at_a_time local:hadoop ${cluster_name}-slave
echo "deployed $slaves_at_a_time slaves"
juju add-relation $juju_env ${cluster_name}-master:namenode ${cluster_name}-slave:datanode
juju add-relation $juju_env ${cluster_name}-master:jobtracker ${cluster_name}-slave:tasktracker
for i in {1..9}; do
add_more_units $slaves_at_a_time ${cluster_name}-slave
echo "deployed $slaves_at_a_time slaves at $(timestamp)"
done
}
deploy_cluster() {
local cluster_name=$1
local master_config="$juju_root/etc/hadoop-master.yaml"
local master_size="instance-type=m1.large"
juju deploy $juju_env --repository $juju_repo --constraints $master_size --config $master_config local:hadoop ${cluster_name}-master
deploy_slaves ${cluster_name}
juju expose $juju_env ${cluster_name}-master
}
main() {
echo "deploying stack at $(timestamp)"
juju bootstrap $juju_env --constraints="instance-type=m1.xlarge"
sleep 120
deploy_cluster hadoop
echo "done at $(timestamp)"
}
main $*
exit 0
We experimented with more clever ways of doing the spinup (too little coffee at this point of the night)… but the real fix is to get juju to take advantage of multiplicity in api calls. Until then, timed batches work just fine.
Juju spun the cluster up in about 2 and a half hours. It had about 380TB of HDFS storage
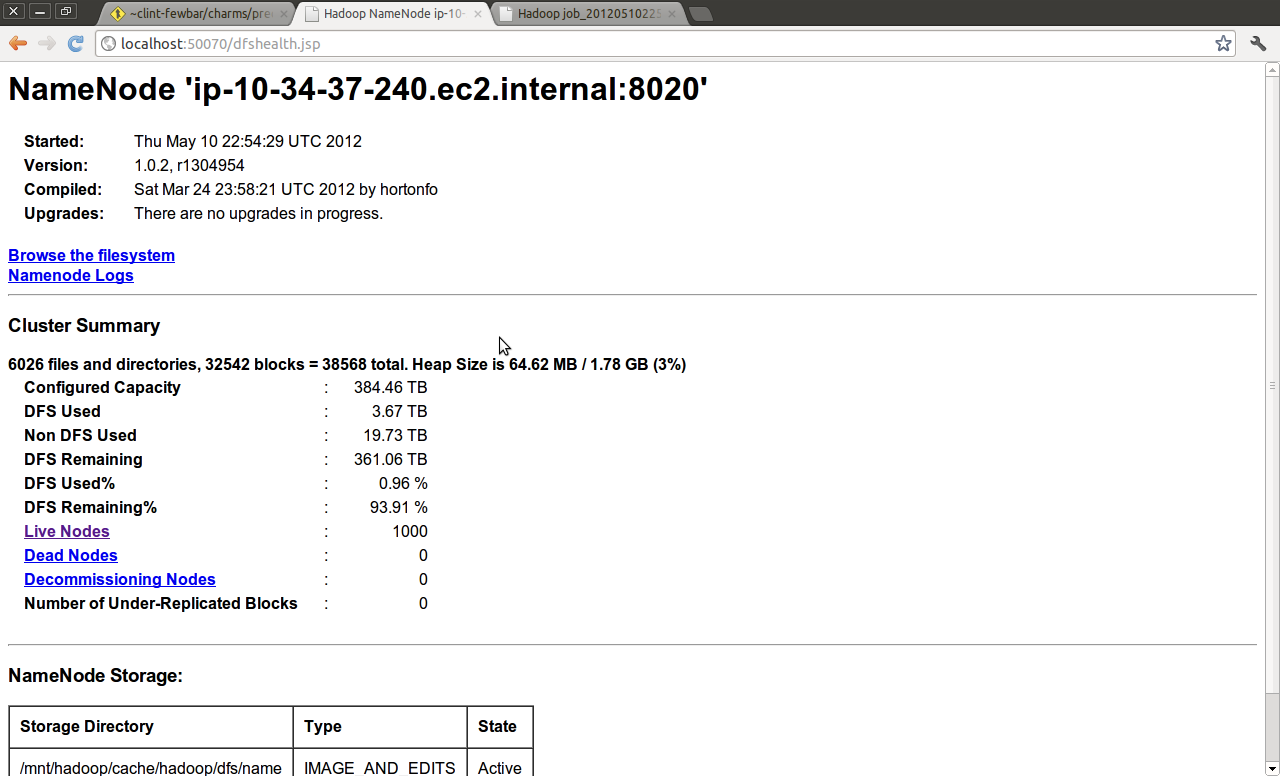
The terasort job that was run from the script above with
SIZE=10000000000
NUM_MAPS=3000
NUM_REDUCES=3000
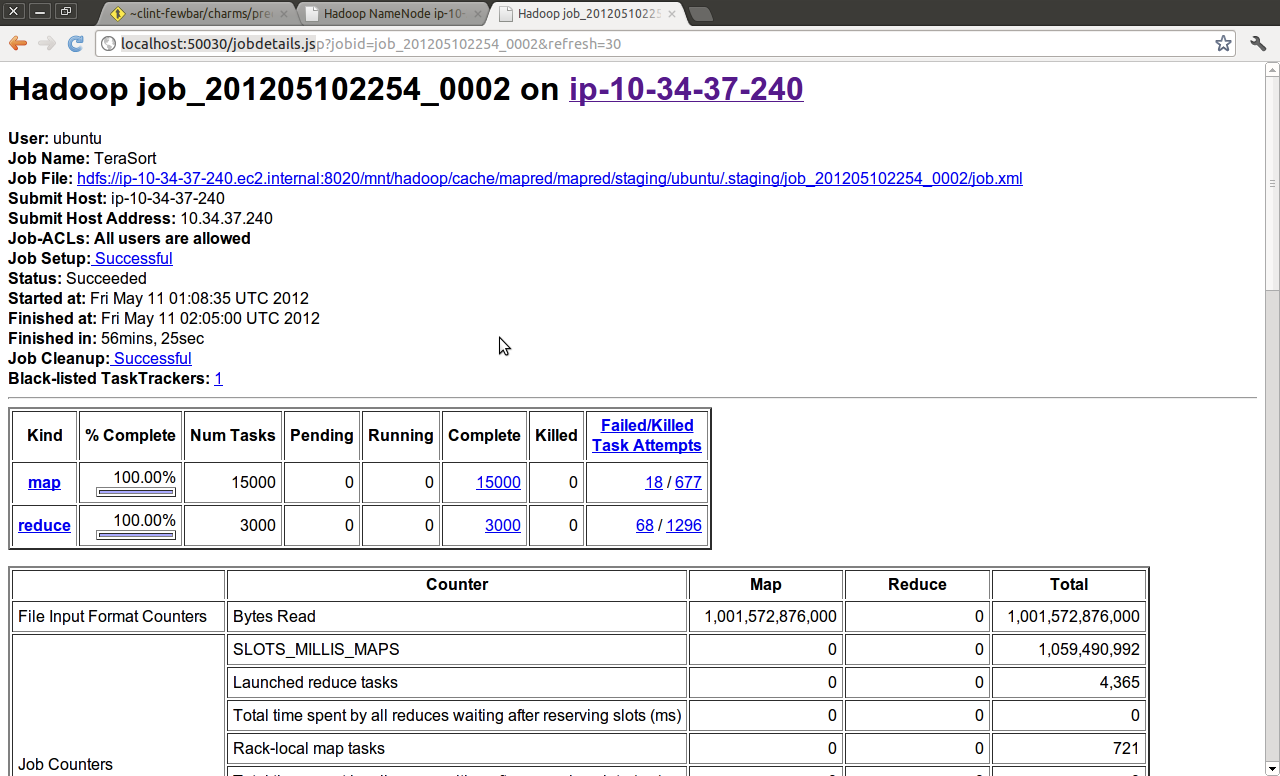
eventually completed.
2000 nodes
After the 1000-node run, we chose to clean up from the previous job and just add more nodes to that same cluster.
Again, to get around the api throttling, we added batches of 99 slaves at a time with a 2-minute wait between each batch until we got near 2000 slaves.
This gave us almost 760TB of HDFS storage
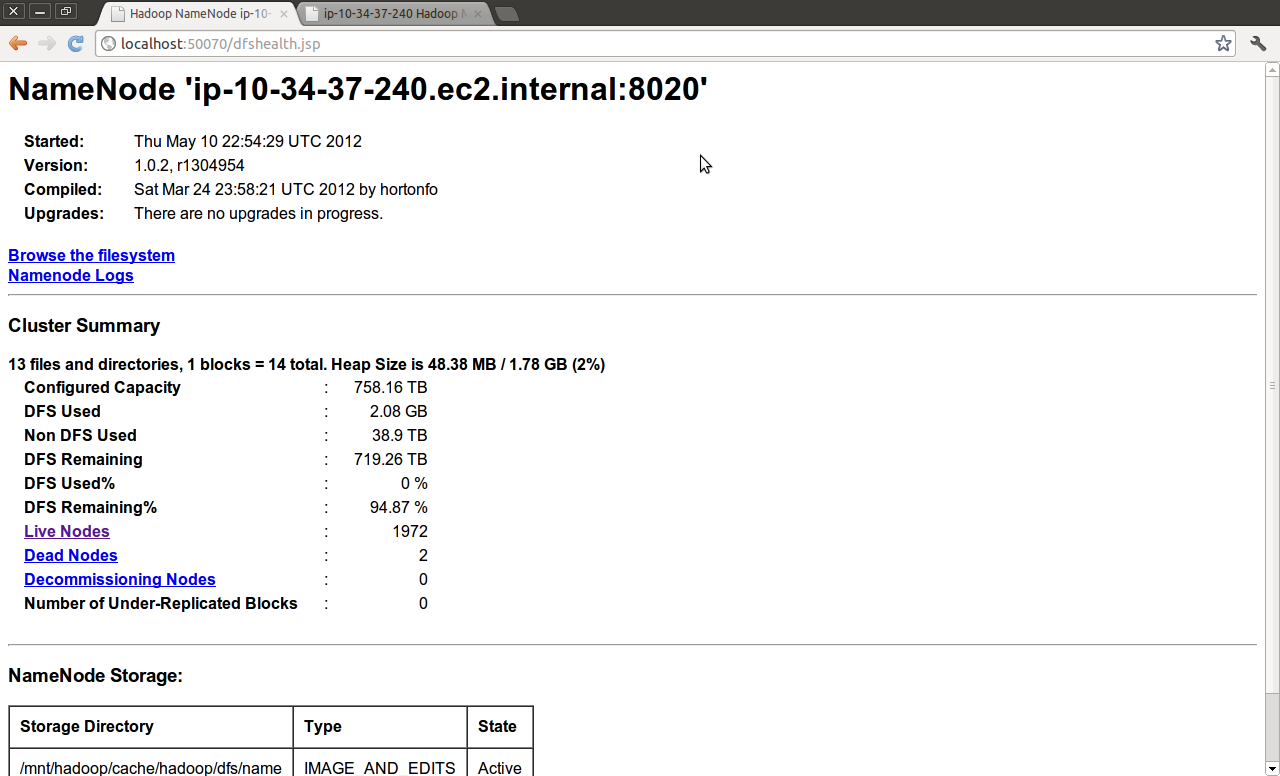
and was running fine
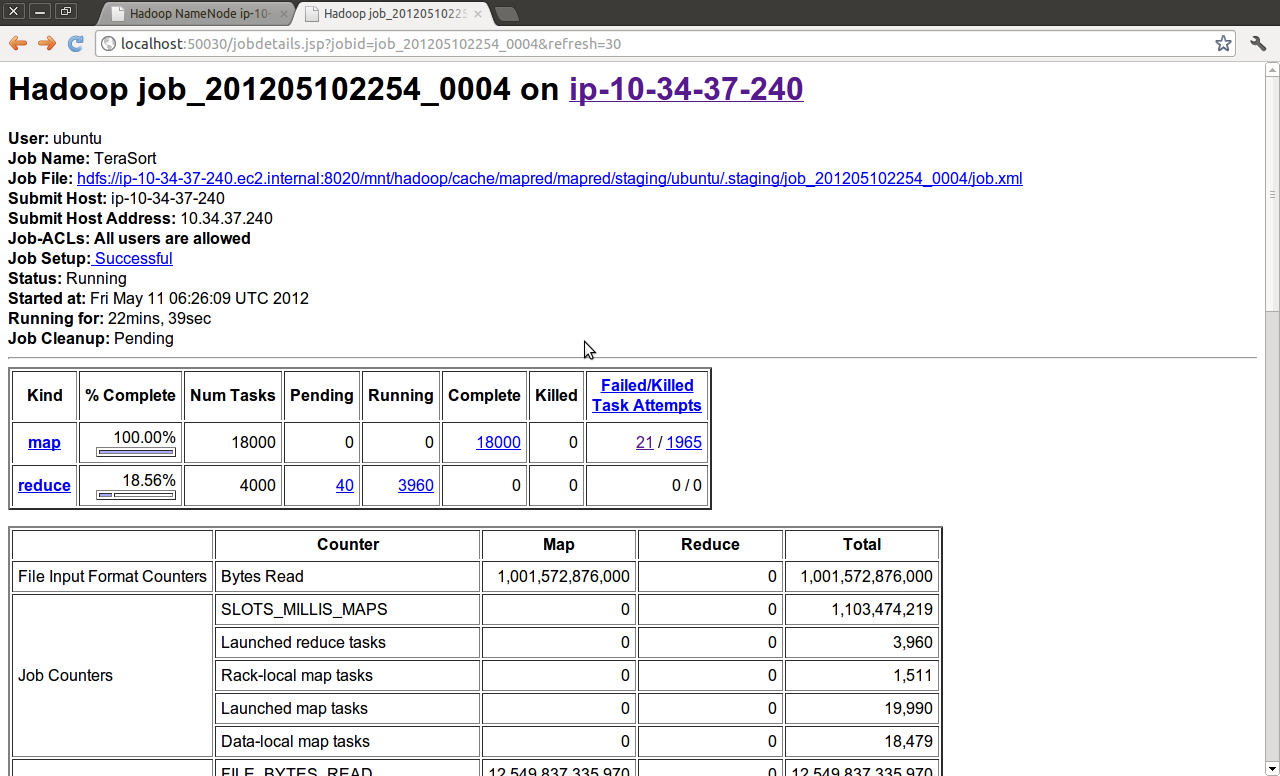
but was stopped early b/c waiting for the job to complete would’ve just been silly at this point. With our naive job config, we’re considerably past the point of diminishing returns for adding nodes to the actual terasort, and we’d captured the profiling info we needed at this point.
Juju spun up 1972 slaves in just over seven hours total. Profiling showed that juju was spending a lot of time serializing stuff into zookeeper nodes using yaml. It looks like python’s yaml implementation is python, and not just wrapping libyaml. We tested a smaller run replacing the internal yaml serialization with json.. Wham! two orders of magnitude faster. No particular surprise.
Lessons Learned
Ok, so at the end of the day, what did we learn here?
What we did here is the way developing for performance at scale should be done… start with a naive, flexible approach and then spend time and effort obtaining real profiling information. Follow that with optimization decisions that actually make a difference. Otherwise it’s all just a crapshoot based on where developers think the bottlenecks might be.
Things to do to juju as a result of these tests:
- streamline our implementation of ‘-n’ options
- the client should pass the multiplicity to the provisioning agent
- the provisioning agent should pass the multiplicity to the EC2 api
- don’t use yaml to marshall data in and out of zookeeper
- replace per-instance security groups with per-instance firewalls
What’s Next?
So that’s a big enough bite for one round of scale testing.
Next up:
- land a few of the changes outlined above into trunk. Then, spin up another round of scale tests to look at the numbers.
- more providers (other clouds as well as a MaaS lab too)
- regular scale testing?
- can this coincide with upstream scale testing for projects like hadoop?
- test scaling for various services? What does this look like for other stacks of services?
Wishlist
-
find some better test jobs! benchmarks are boring… perhaps we can use this compute time to mine educational data or cure cancer or something?
-
perhaps push juju topology information further into zk leaf nodes? Are there transactional features in more recent versions of zk that we can use?
-
use spot instances on ec2. This is harder because you’ve gotta incorporate price monitoring.
If you have any questions or feedback, please feel free to share it with me on Twitter: @m_3