Hey, so last month we ran scheduling for the Linux Plumbers Conference entirely on juju!
Here’s a little background on the experience.
Along the way, we’ll go into a little more detail about running juju in production than the particular problem at hand might warrant. It’s a basic stack of services that’s only alive for 6-months or so… but this discussion applies to bigger longer-running production infrastructures too, so it’s worth going over here.
The App
So summit is this great django app built for scheduling conferences. It’s evolved over time to handle UDS-level traffic and is currently maintained by a Summit Hackers team that includes Chris Johnston and Michael Hall.
Chris contacted me to help him use juju to manage summit for this year’s Plumbers conference. At the time we started this, the 11.10 version of juju wasn’t exactly blessed for production environments, but we decided it’d be a great opportunity to work things out.
The Stack
A typical summit stack’s got postgresql, the django app itself, and a memcached server.
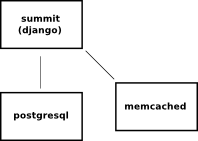
We additionally talked about putting this all behind some sort of a head like haproxy.
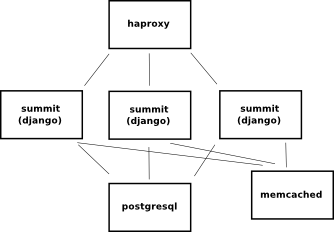
This’d let the app scale horizontally as well as give us a stable point to attach an elastic-ip. We decided to not do this at the time b/c we could most likely handle the peak conference load with a single django service-unit provided we slam select snippets of the site into memcached.
This turned out to be true load-wise, but it really would’ve been a whole lot easier to have a nice constant haproxy node out there to tack the elastic-ip to. During development (charm, app, and theme) you want the freedom to destroy a service and respawn it without having to use external tools to go around and attach public IP addresses to the right places. That’s a pain. Also, if there’s a sensitive part of this infrastructure in production, it wouldn’t be postgresql, memcached, or haproxy… the app itself would be the most likely point of instability, so it was a mistake to attach the elastic-ip there.
The Environment
choice of cloud
We chose to use ec2 to host the summit stack… mostly a matter of convenience. The juju openstack-native provider wasn’t completed when we spun up the production environment for linuxplumbers and we didn’t have access to a stable private ubuntu cloud running the openstack-ec2-api at the time. All of this has subsequently landed, so we’d have more options today.
the charms
We forked Michael Nelson’s excellent django charm to create a summit-charm and freely specialized it for summit.
Note that we’re updating this charm for 12.04 here, but this will probably go away in the near future and we’ll just use a generic django charm. It turns out we didn’t do too much here that won’t apply to django apps in general, but more on that another time.
There was nothing special about our tuning of postgresql or memcached. We just used the services provided by the canned charms. These sort of peripheral services aren’t the kind of charms you’re likely to be making changes to or tweaking outside of their exposed config parameters. I know jack about memcached, so I’ll defer to the experts in this regard. Similarly for postgresql… and haproxy if we used it in this stack.
The summit charm is a little different. It’s something we were continuing to tweak during development. Perhaps with future more generic django charm versions, we won’t need to tweak the charm itself… just configure it.
We used a “local” repository for all charms because the charm store hadn’t landed when we were setting this up. Well, now that the charm store is live, you can just deploy the canned charms straight from the store
`juju deploy -e summit memcached`
and keep the ones you want to tweak in a local repository…
`juju deploy -e summit --repository ~/charms local:summit`
all within the same environment. It works out nicely.
control environment
We had multiple people to manage the production summit environment. What’s the best way to do that? It turns out juju supports this pretty well right out of the box. There’s an environment config for the set of ssh public keys to inject into everything in the environment as it starts up… you can read more about that on askubuntu.
Note that this is only useful to configure at the beginning of the stack. Once you’re up, adding keys is problematic. I don’t even recommend trying b/c of the risk of getting undetermined state for the environment. i.e., different nodes with different sets of keys depending on when you changed the keys relative to what actions you’ve performed on the environment. It’s a problem.
What I recommend now is actually to use another juju environment… (and no, we’re not paid to promote cloud providers by the instance :) I wish! ) a dedicated “control” environment. You bootstrap it, then set up a juju client that controls the main production environment. Then set up a shared tmux session that any of the admins for the production environment can use:
Adding/changing the set of admin keys is then done in a single place. This technique isn’t strictly necessary, but it was certainly worth it here with different admins having various different levels of familiarity with the tools. I started it as a teaching tool, left it up because it was an easy control dashboard, and now recommend it because it works so well.
it’s chilly in here
Yeah, so during development you break things. There were a couple of times using 11.10 juju that changes to juju core prevented a client from talking to an existing stack. Aargh! This wasn’t going to fly for production use.
The juju team has subsequently done a bunch to prevent this from happening, but hey we needed production summit working and stable at the time. The answer… freeze the code.
Juju has an environment config option juju-origin to specify where to
get the juju installed on all instances in the environment. I branched juju
core to lp:~mark-mims/juju/running-summit and just worked straight from there
for the lifetime of the environment (still up atm). Easy enough.
Now the tricky part is to make sure that you’re always using the
lp:~mark-mims/juju/running-summit version of the juju cli when talking to the
production summit environment.
I set up
#!/bin/bash
export JUJU_BRANCH=$HOME/src/juju/running-summit
export PATH=$JUJU_BRANCH/bin:$PATH
export PYTHONPATH=$JUJU_BRANCH
which my tmuxinator config sources into every pane in my summit tmux session.
This was also done on the summit-control instance so it’s easy to make sure
we’re all using the right version of the juju cli to talk to the production
environment.
backups
The juju ssh subcommand to the rescue. You can do all your standard ssh
tricks…
juju ssh postgresql/0 'su postgres pg_dump summit' > summit.dump
… on a cronjob. Juju just stays out of the way and just helps out a bit with the addressing. Real version pipes through bzip2 and adds timestamps of course.
Of course snapshots are easy enough too via euca2ools, but the pgsql dumps themselves turned out to be more useful and easy to get to in case of a failover.
debugging
The biggest debugging activity during development was cleaning up the app’s theming. The summit charm is configured to get the django app itself from one application branch and the theme from a separate theme branch.
So… ahem… “best practice” for theme development would’ve been to develop/tweak the theme locally, then push to the branch. A simple
juju set --config=summit.yaml summit/0
would update config for the live instances.
Well… some of the menus from the base template used absolute paths so it was simpler to cheat a bit early in the process to test it all in-place with actual dns names. Had we been doing this the “right” way from the beginning we would’ve had much more confidence in the stack when practicing recovery and failover later in the cycle… we would’ve been doing it all since day one.
Another thing we had to do was manually test memcached. To test out caching we’d ssh to the memcached instance, stop the service, run memcached verbosely in the foreground. Once we determined everything was working the way we expected, we’d kill it and restart the upstart job.
This is a bug in the memcached charm imo… the option to temporarily run verbosely for debugging should totally be a config option for that service. It’d then be a simple matter of
juju set memcached/0 debug=true
and then
juju ssh memcached/0
to watch some logs. Once we’re convinced it’s working the way it should
juju set memcached/0 debug=false
should make it performant again.
Next time around, we should take more advantage of juju set config to
update/reconfigure the app as we made changes… and generally implement a
better set of development practices.
monitoring
Sorely lacking. “What? curl doesn’t cut it?”… um… no.
planning for failures
Our notion of failover for this app was just a spare set of cloud credentials and a tested recovery plan.
The plan we practiced was…
- bootstrap a new environment (using spare credentials if necessary)
- spin up the summit stack
- ssh to the new
postgresql/0and drop the db (Note: the postgresql charm should be extended to accept a config parameter of a storage url, S3 in this case, to slurp the db backups from) -
restore from offsite backups… something along the lines of
cat summit-$timestamp.dump.bz2 juju ssh -e failover postgresql/0 ‘bunzip2 -c su - postgres pgsql summit’
In practice, that took about 10-15minutes to recover once we started acting. Given the additional delay between notification and action, that could spell an hour or two of outtage. That’s not so great.
Juju makes other failover scenarios cheaper and easier to implement than they used to be, so why not put those into place just to be safe? Perhaps the additional instance costs for hot-spares wouldn’t’ve been necessary for the entire 6-months of lead-time for scheduling and planning this conference, but they’d certainly be worth the spend during the few days of the event itself. Juju sort of makes it a no-brainer. We should do more posts on this one issue… the game has changed here.
Lessons Learned
What would we do differently next time? Well, there’s a list :).
- use the stable ppa… instead of freezing the code
- sit the app behind haproxy
- use s3fs or equivalent subordinate charm to manage backups instead of just sshing them off the box
- better monitoring… we’ve gotten a great set of monitoring charms recently… thanks Clint!
- log aggregation would’ve been a little bit of overkill for this app, but next time might warrant it
- it’s cheap to add failover with juju… just do it
- maybe follow a development process a little more carefully next time around :)
- we’ll soon have access to a production-stable private ubuntu cloud for these sorts of apps/projects
If you have any questions or feedback, please feel free to share it with me on Twitter: @m_3